In the world of modern software systems, keeping track of how your applications perform is essential. Observability has become a critical practice for development and operations teams to maintain the health and reliability of complex systems. But what exactly is observability, and why is it crucial in software infrastructure?
Observability refers to the ability to understand the internal state of a system by analyzing its outputs. These outputs, often represented by metrics, logs, and traces, help organizations gain deep insights into system behavior, enabling effective monitoring, debugging, and optimization. In this article, we explore observability, its components, and how it helps you understand what, why, and how things are happening within your application infrastructure.
What is Observability?
Observability is the practice of gaining insights into a system’s internal state based on its external outputs. Unlike traditional monitoring, which primarily focuses on whether a system is up and running, observability provides detailed information on the underlying conditions that affect the system’s performance. It helps answer questions such as:
- What is happening within the system?
- Why is it happening?
- How is the system responding?
Observability is particularly important for modern, distributed systems that may involve microservices, multiple services, containers, and cloud infrastructure. By enhancing observability, developers and operations teams can better diagnose issues, understand user experience, and improve system reliability.
The Three Pillars of Observability
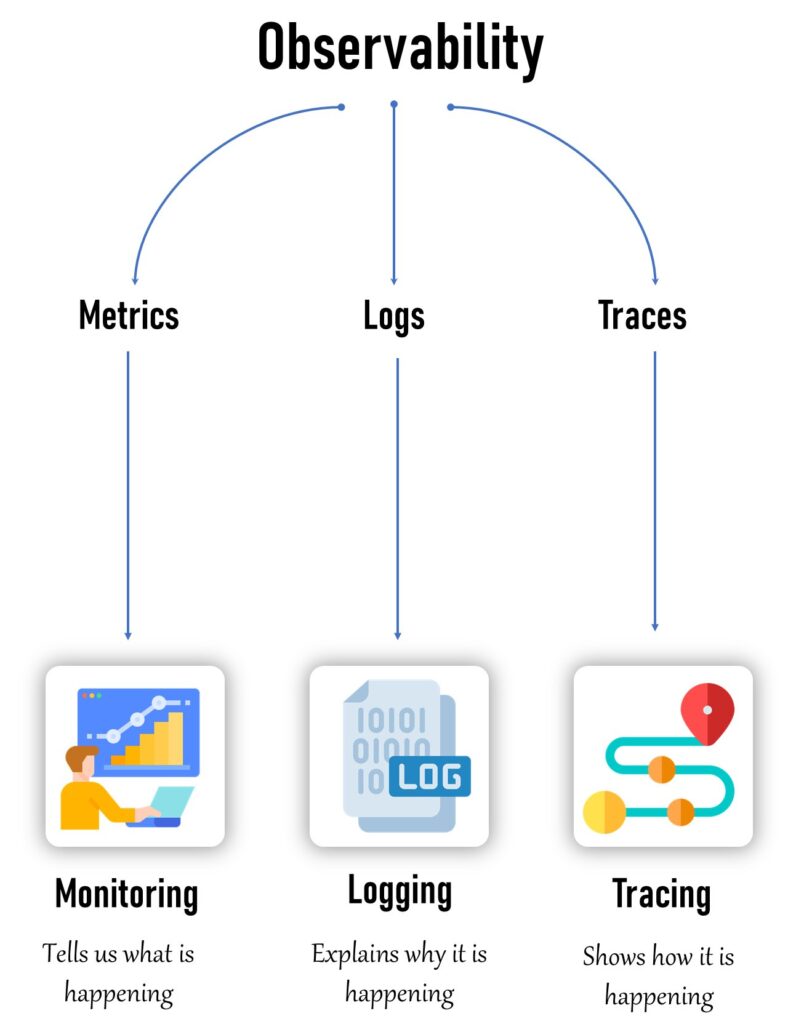
Observability is composed of three core pillars that provide a complete view of the system’s state: Metrics, Logs, and Traces. These three components complement each other, allowing for better insights into application health and performance.
1. Metrics: Monitoring the System’s Health
Metrics are numerical measurements that provide information on the current state of the system. They tell us what is happening within a system and are instrumental in tracking the performance and health of various components of the infrastructure.
- Definition: Metrics are quantifiable data points that are continuously collected over time. Examples include CPU usage, memory consumption, network throughput, error rates, and request response times.
- Use Case: Metrics are used to detect trends in performance, identify bottlenecks, and determine resource utilization.
- Monitoring and Alerts: Metrics are crucial for setting alerts. When a metric value crosses a predefined threshold (e.g., CPU usage exceeds 90%), alerts can be triggered, allowing operations teams to take preventive measures before the system experiences significant issues.
- Advantages: Metrics offer a high-level view of the system’s health and are suitable for tracking KPIs (Key Performance Indicators) over time. They can be used to determine whether the system is functioning within expected parameters.
In summary, metrics are the foundation of monitoring a system’s health. They provide visibility into the system’s overall state, highlight trends, and help ensure that critical components are performing optimally.
2. Logs: Understanding the Why Behind Events
Logs represent detailed, timestamped records of events that have occurred in the system. Logs tell us why something happened, providing granular details about system events, transactions, and errors.
- Definition: Logs are sequences of records generated by an application to capture events, including errors, debugging information, system warnings, and security events.
- Use Case: Logs are used to identify the cause of specific events. For example, if an application crashes, logs can provide information on the error that led to the failure, making them crucial for troubleshooting.
- Debugging: Logs are critical for debugging purposes, especially when dealing with failures or unexpected behaviors. They capture error messages, input parameters, and stack traces, which help developers diagnose issues.
- Centralized Logging: Logs can be centralized using tools like Elasticsearch or Splunk to aggregate data from multiple services. This allows for efficient searching and correlation of log events across a distributed system.
While metrics offer a high-level view, logs provide the contextual information needed to understand why things are happening. Logs are essential for deep-dive troubleshooting, enabling developers to trace the root cause of problems and rectify them effectively.
3. Traces: Visualizing the Flow of Requests
Traces are crucial for visualizing how things are happening within the system. They show how requests flow across services, especially in distributed architectures where multiple components interact with each other.
- Definition: A trace represents the journey of a request as it traverses different components of a distributed system. Traces consist of spans, where each span represents an operation that occurs within a specific component or service.
- Use Case: Traces help monitor the flow of requests between services, allowing teams to visualize latency and pinpoint the source of bottlenecks or delays. Tracing enables a deeper understanding of how a transaction or request propagates through different microservices.
- End-to-End Visibility: Traces are crucial in microservice-based architectures as they provide end-to-end visibility into system behavior. They help identify how different services interact and where issues, such as increased latency, occur.
- Example: If an end user is experiencing slow performance in an e-commerce application, traces can be used to determine which service or component caused the delay. By analyzing the flow of the request, developers can identify which service was responsible for the increased response time.
Tracing is critical for improving performance, especially in distributed systems, by understanding how transactions are processed across the entire infrastructure.
How Metrics, Logs, and Traces Work Together
The three pillars of observability—metrics, logs, and traces—work together to provide a holistic view of system performance and behavior.
- Metrics provide insights into what is happening. For example, they indicate high CPU usage or a spike in response times.
- Logs provide contextual information to explain why an event occurred, such as an application throwing an exception or service not being able to connect to a database.
- Traces visualize how requests flow across services, allowing developers to analyze end-to-end transactions and identify bottlenecks.
In combination, metrics, logs, and traces provide a complete picture of system health, enabling teams to monitor, debug, and optimize effectively. Metrics may indicate a problem, logs provide the context, and traces allow the visualization of the root cause.
Importance of Observability in Modern Applications
Observability is critical for modern, distributed applications that require comprehensive monitoring and debugging capabilities. The rise of microservices, cloud-based infrastructure, and containerization has led to increased system complexity, necessitating an approach that goes beyond traditional monitoring.
- Microservices and Distributed Systems: Microservice-based architectures involve multiple independent services that interact through APIs. Tracing is crucial for understanding interdependencies and finding the root cause of issues in such architectures.
- Scalability: Observability helps maintain system health as an application scales. By monitoring metrics and logs, teams can ensure that scaling events do not adversely affect performance.
- Improved Reliability: Observability enhances reliability by providing early detection of issues and empowering teams to take preventive measures before users are affected.
Observability is not just about identifying issues when they arise; it is about proactively understanding and monitoring system behavior to ensure a reliable and high-performing user experience.
Best Practices for Achieving Observability
To fully leverage observability in an application infrastructure, consider the following best practices:
1. Establish Monitoring Thresholds and Alerts
Define meaningful metrics and thresholds for alerts to identify potential issues before they become critical problems. Alerts should focus on performance degradation, resource utilization, and unusual activities.
2. Use Centralized Logging
Use a centralized logging system to aggregate logs from multiple components into one location. Centralized logging tools like ELK Stack (Elasticsearch, Logstash, and Kibana) or Splunk make it easier to search and correlate logs from different services.
3. Implement Distributed Tracing
In distributed systems, implement distributed tracing using tools like Jaeger or Zipkin. Tracing helps visualize interactions between services and pinpoint bottlenecks or latency issues.
4. Enable Correlation Between Metrics, Logs, and Traces
Enable correlation between the three observability pillars to provide a seamless debugging experience. Use tags or identifiers (e.g., request IDs) that are shared across metrics, logs, and traces so that information from all three sources can be easily linked.
5. Use Dashboards for Visualization
Visualize metrics and traces using dashboards like Grafana to monitor system health in real time. Dashboards help detect anomalies and assist in root cause analysis.
6. Use Observability Tools
Leverage observability tools like Prometheus, Datadog, and Splunk to manage metrics, logs, and traces effectively. Such tools help provide a cohesive view of system health and offer insights into potential optimization areas.
Read More: What is REST API? A Comprehensive Guide to Understanding RESTful Web Services.
Conclusion
Observability is a powerful capability that helps organizations gain a comprehensive understanding of the inner workings of their application infrastructure. By leveraging the three pillars—metrics, logs, and traces—observability provides visibility into what is happening, why it is happening, and how it is happening in distributed systems.
Metrics provide real-time monitoring of system health, logs capture detailed event information for debugging, and traces show the flow of requests across components. Together, these three components provide a 360-degree view of system behavior, enabling proactive monitoring, rapid troubleshooting, and enhanced reliability.
In modern, distributed, and cloud-based infrastructures, observability is no longer an option—it is a necessity for ensuring the health, performance, and reliability of software systems. By following best practices for observability and utilizing the right tools, organizations can deliver high-quality user experiences while maintaining system resilience.